Huffman codes: examples, applications
At the moment, few people think about the fact,how compression works. Compared to the past, using a personal computer has become much easier. And practically every person working with the file system uses archives. But few people think about how they work and on what principle is the compression of files. The very first version of this process was the Huffman codes, and they are still used in various popular archivers. Many users do not even think how easy it is to compress the file and according to which scheme it works. In this article, we'll look at how compression is done, what nuances help to speed up and simplify the encoding process, and we'll figure out what the principle of constructing a coding tree is.
History of the algorithm
The very first algorithm for an effectivecoding of electronic information was the code proposed by Huffman in the middle of the twentieth century, namely in 1952. It is currently the main basic element of most programs created to compress information. At the moment, one of the most popular sources using this code are ZIP, ARJ, RAR archives and many others.
The principle of efficient coding
The basis for the Huffman algorithm is a scheme,It allows to replace the most probable, most frequently encountered symbols with codes of a binary system. And those that are less common are replaced with longer codes. The transition to long Huffman codes occurs only after the system uses all the minimum values. This technique allows you to minimize the length of the code for each character of the original message as a whole.
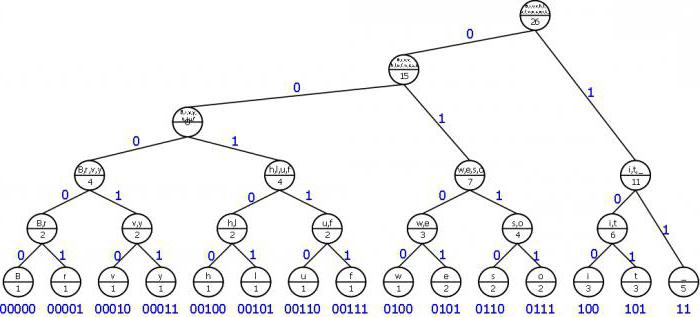
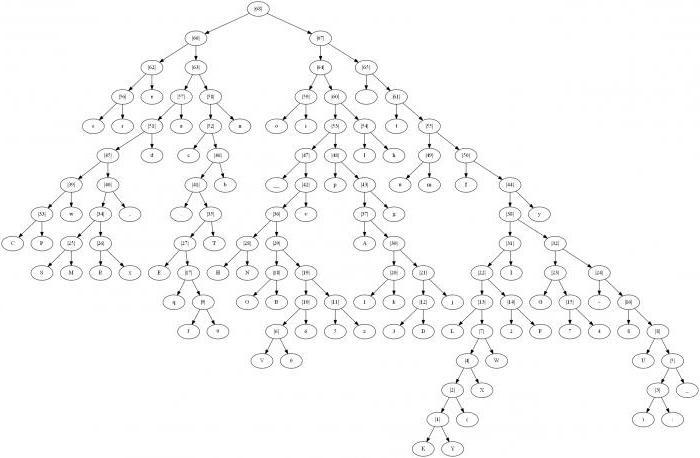
Huffman's code, example
To illustrate the algorithm, let us takea graphic version of the construction of a code tree. To use this method was effective, it is worthwhile to clarify the definition of some values necessary for the concept of this method. The set of arcs and nodes that are directed from node to node is usually called a graph. The tree itself is a graph with a set of certain properties:
- in each node can enter no more than one of the arcs;
- one of the nodes must be the root of the tree, that is, no arc should enter it at all;
- if from the root to start moving along arcs, this process should allow to get completely into any of the nodes.

Algorithm for constructing a tree according to Huffman
The construction of the Huffman code is made from lettersof the input alphabet. A list of those nodes that are free in the future code tree is created. The weight of each node in this list should be the same as the probability of occurrence of the letter of the message corresponding to this node. In this case, among the few free nodes of the future tree, the one that weighs least is chosen. At the same time, if the minimum indicators are observed in several nodes, then it is possible to choose freely any of the pairs.
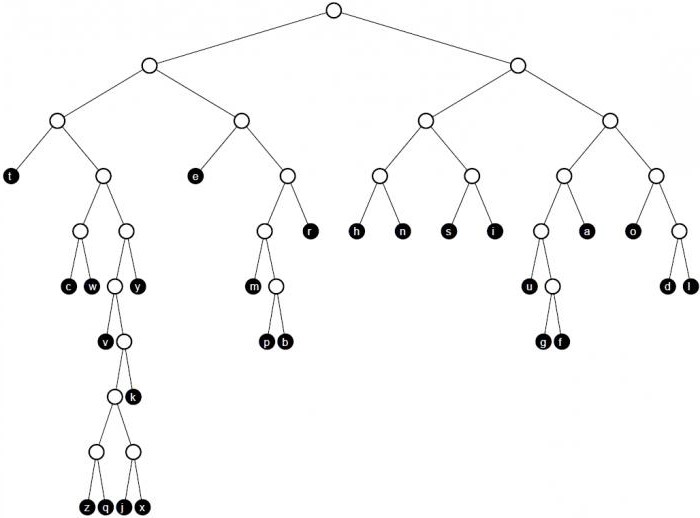
Improved compression efficiency
To improve compression efficiency, you need totime to build a code tree to use all the data regarding the likelihood of letters in a particular file attached to a tree, and prevent them from being scattered across a large number of text documents. If you first go through this file, you can immediately calculate the statistics of how often the letters from the object to be compressed are found.
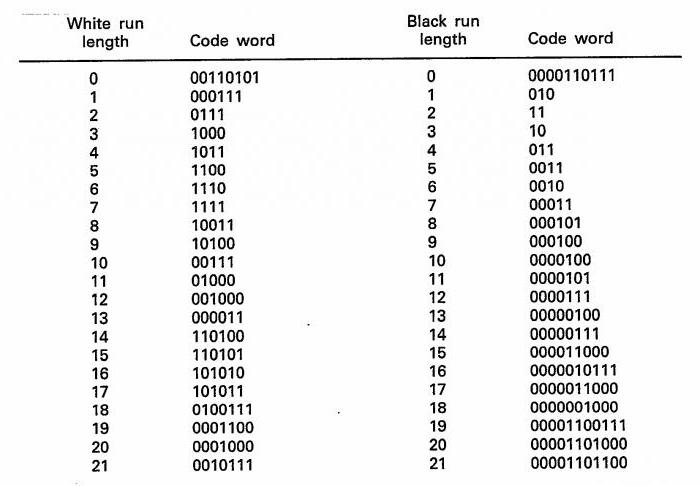
Accelerating the compression process
To speed up the algorithm, the definition of lettersshould be carried out not according to the probability of occurrence of a letter, but by the frequency of its occurrence. Due to this, the algorithm becomes easier, and work with it is greatly accelerated. It also avoids operations related to floating commas and division.
Conclusion
Huffman codes - simple and long-establishedan algorithm that is still used by many well-known programs and companies. Its simplicity and clarity make it possible to achieve effective results of compressing files of any size and significantly reduce the disk space they occupy. In other words, the Huffman algorithm is a long-studied and well-developed scheme, the relevance of which does not decrease to this day.